


I hope you that you all aware of robots.txt, do you ever checked robots.txt file in major websites?. Check this Delicious robots.txt file, which is used as an example to show the complex & concept of robots.txt file by one of my colleague. I am just curious to check the robots.txt in my client sites and in other sites too. When I checked the same in Twitter, I came to know a new term called ‘crawl-delay’. This directive was used by Twitter in their robots.txt file.
Check out the robots.txt file of Twitter below,

I am not aware of that term before and then I started to read about that. I like to share the points that I have read and I welcome you to share your points & views to make this blog as a helpful one for others.
What is Crawl-delay?
Lets come to business. What is Crawl-delay?. Here is the easy definition from Wikipedia,
“Several major crawlers support a Crawl-delay parameter, set to the number of seconds to wait between successive requests to the same server”
Crawl-delay is the directive used to by major websites who has very frequent content updation. In the case of Twitter; Googlebot and other major bots love to visit Twitter since all they are providing real-time updates in their SERP. Since frequent visit by all bots will cause over-load to their servers, Twitter setting a time-interval for each crawling by using crawl-delay directive.
Facts about Crawl-delay:
- Crawl-delay’s major concern is to accommodate with web server load issues.
- This directive can only be useful for larger websites with very frequent updates. Smaller website won’t need this.
- YahooSlurp, MSNBot will support ‘Crawl-delay’ directive
- Since all other bots are not supporting this, it is advised to have robots.txt file as,
- User-agent: MSNBot
- Crawl-delay: 5
- And its is not advised to have like this,
- User-agent: *
- Crawl-delay: 5
- The time represented in crawl-delay respective is in ‘seconds’
- Since all servers hosting more than one domain, it is advised to have crawl-delay as more than 1 seconds. Having ‘crawl-delay’ as “1 sec” wont reduce the over-load burden to the servers.
- Since factors like number of pages in a website, bandwidth of the website, content of the website affect crawling of any website, using ‘crawl-delay’ directive will help to solve the server over-loading issues.
- Though it is supported by major bots, it is not advisable one and sometimes called as ‘non-standard’ also.
If you feel anything that I have missed in this blog about ‘Crawl-delay’, please share it in comments.
Disclaimer: The post is completely based on individual thoughts and SEO Services Group bears no responsibilities for the thoughts reflected in the post.


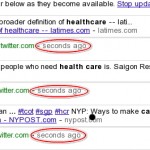





Why does it matter if you have it like this:
* User-agent: *
* Crawl-delay: 5
Find the below link, Even Google doesn't support the crawl-delay directives, so better we specify the crawl-delay directive for specific crawlers alone.
http://www.google.com/support/forum/p/Webmasters/…